ES - Elasticsearch 在各大互联网公司真实应用案例
国内现在有大量的公司都在使用 Elasticsearch,包括携程、滴滴、今日头条、饿了么、360安全、小米、vivo等诸多知名公司。

除了搜索之外,结合Kibana、Logstash、Beats,Elastic Stack还被广泛运用在大数据近实时分析领域,包括日志分析、指标监控、信息安全等多个领域。
它可以帮助你探索海量结构化、非结构化数据,按需创建可视化报表,对监控数据设置报警阈值,甚至通过使用机器学习技术,自动识别异常状况。

1. 京东到家订单中心 Elasticsearch 演进历程
京东到家订单中心系统业务中,无论是外部商家的订单生产,或是内部上下游系统的依赖,订单查询的调用量都非常大,造成了订单数据读多写少的情况。
京东到家的订单数据存储在MySQL中,但显然只通过DB来支撑大量的查询是不可取的,同时对于一些复杂的查询,Mysql支持得不够友好,所以订单中心系统使用了Elasticsearch来承载订单查询的主要压力。
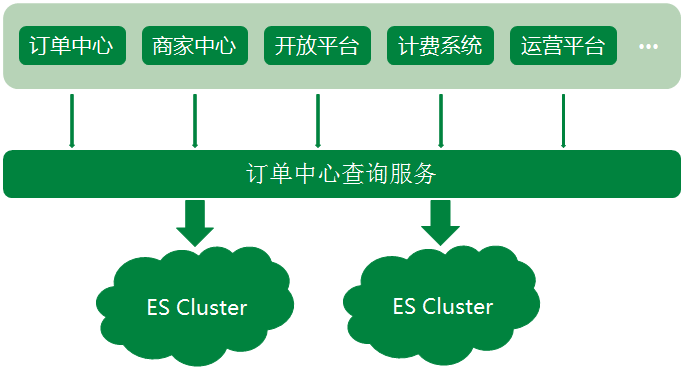
Elasticsearch 作为一款功能强大的分布式搜索引擎,支持近实时的存储、搜索数据,在京东到家订单系统中发挥着巨大作用,目前订单中心ES集群存储数据量达到10亿个文档,日均查询量达到5亿。
随着京东到家近几年业务的快速发展,订单中心ES架设方案也不断演进,发展至今ES集群架设是一套实时互备方案,很好的保障了ES集群读写的稳定性。
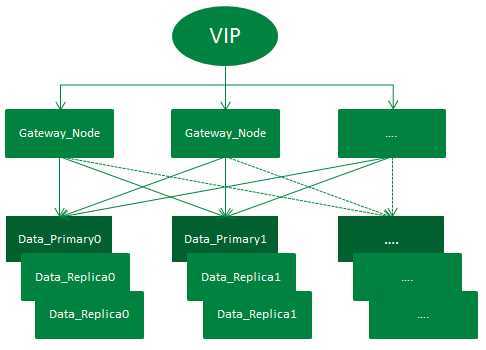
如上图,订单中心ES集群架设示意图。整个架设方式通过VIP来负载均衡外部请求,第一层gateway节点实质为ES中client node,相当于一个智能负载均衡器,充当着分发请求的角色。
第二层为data node,负责存储数据以及执行数据的相关操作。整个集群有一套主分片,二套副分片(一主二副),从网关节点转发过来的请求,会在打到数据节点之前通过轮询的方式进行均衡。集群增加一套副本并扩容机器的方式,增加了集群吞吐量,从而提升了整个集群查询性能。
当然分片数量和分片副本数量并不是越多越好,在此阶段中,对选择适当的分片数量做了进一步探索。
分片数可以理解为Mysql中的分库分表,而当前订单中心ES查询主要分为两类:单ID查询以及分页查询。
分片数越大,集群横向扩容规模也更大,根据分片路由的单ID查询吞吐量也能大大提升,但对于聚合的分页查询性能则将降低。分片数越小,集群横向扩容规模更小,单ID的查询性能也将下降,但对于分页查询,性能将会得到提升。
所以如何均衡分片数量和现有查询业务,我们做了很多次调整压测,最终选择了集群性能较好的分片数。
由于大部分ES查询的流量都来源于近几天的订单,且订单中心数据库数据已有一套归档机制,将指定天数之前已经关闭的订单转移到历史订单库。
架构的快速迭代源于业务的快速发展,正是由于近几年到家业务的高速发展,订单中心的架构也不断优化升级。
2. 携程Elasticsearch应用案例
2.1. 酒店订单Elasticsearch实战
选择对分片后的数据库建立实时索引,把查询收口到一个独立的 Web Service,在保证性能的前提下,提升业务应用查询时的便捷性。
最终我们选择了 Elasticsearch,看重的是它的轻量级、易用和对分布式更好的支持,整个安装包也只有几十兆。
http://developer.51cto.com/art/201807/579354.htm
2.2. 机票ElasticSearch集群运维
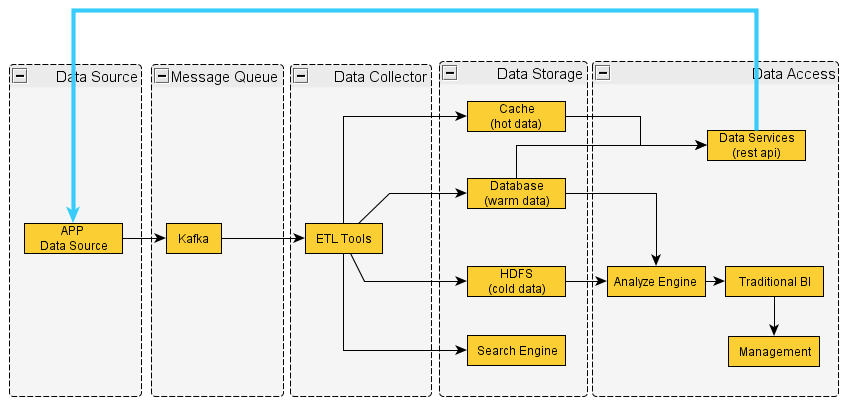
这个是比较通用的数据的流程,一般会通过Kafka分离产生数据的应用程序和后面的平台,通过ETL落到不同的地方,按照优先级和冷热程度采取不同的存储方式。
一般来说,冷数据存放到HDFS,如果温数据、或者热数据会采用Database以及Cache。一旦数据落地,我们会做两方面的应用
第一个方面的应用是传统BI,比如会产生各种各样的报表,报表的受众是更高的决策层和管理层,他们看了之后,会有相应的业务调整和更高层面的规划或转变。
这个使用路径比较传统的,在数据仓库时代就已经存在了。现在有一种新兴的场景就是利用大数据进行快速决策,数据不是喂给人的,数据分析结果由程序来消费,其实是再次的反馈到数据源头即应用程序中,让他们基于快速分析后的结果,调整已有策略,这样就形成了一个数据使用的循环。
这样我们从它的输入到输出会形成一种闭环,而且这个闭环全部是机器参与的,这也是为什么去研究这种大规模的,或者快速决策的原因所在。
如果数据最终还会给人本身来看的话,就没有必要更新那么快,因为一秒钟刷新一次或者10秒钟刷新一次对人是没有意义的,因为我们脑子不可能一直转那么快,基于数据一直的做调整也是不现实的,但是对机器来讲,就完全没有问题。
http://www.sohu.com/a/199672012_411876
2.3. 大规模Elasticsearch集群管理
目前,我们最大的日志单集群有120个data node,运行于70台物理服务器上。数据规模如下:
- 单日索引数据条数600亿,新增索引文件25TB (含一个复制片则为50TB)
- 业务高峰期峰值索引速率维持在百万条/秒
- 历史数据保留时长根据业务需求制定,从10天 - 90天不等
- 集群共3441个索引、17000个分片、数据总量约9300亿, 磁盘总消耗1PB
https://www.jianshu.com/p/6470754b8248
3. 去哪儿:订单中心基于elasticsearch解决方案
15年去哪儿网酒店日均订单量达到30w+,随着多平台订单的聚合日均订单能达到100w左右。
原来采用的热表分库方式,即将最近6个月的订单的放置在一张表中,将历史订单放在在history表中。history表存储全量的数据,当用户查询的下单时间跨度超过6个月即查询历史订单表,此分表方式热表的数据量为4000w左右,当时能解决的问题。但是显然不能满足携程艺龙订单接入的需求。
如果继续按照热表方式,数据量将超过1亿条。全量数据表保存2年的可能就超过4亿的数据量。所以寻找有效途径解决此问题迫在眉睫。
由于对这预计4亿的数据量还需按照预定日期、入住日期、离店日期、订单号、联系人姓名、电话、酒店名称、订单状态……等多个条件查询。所以简单按照某一个维度进行分表操作没有意义。
Elasticsearch分布式搜索储存集群的引入,就是为了解决订单数据的存储与搜索的问题。
对订单模型进行抽象和分类,将常用搜索字段和基础属性字段剥离。DB做分库分表,存储订单详情;Elasticsearch存储搜素字段。
订单复杂查询直接走Elasticsearch,基于OrderNo的简单查询走DB,如下图所示。
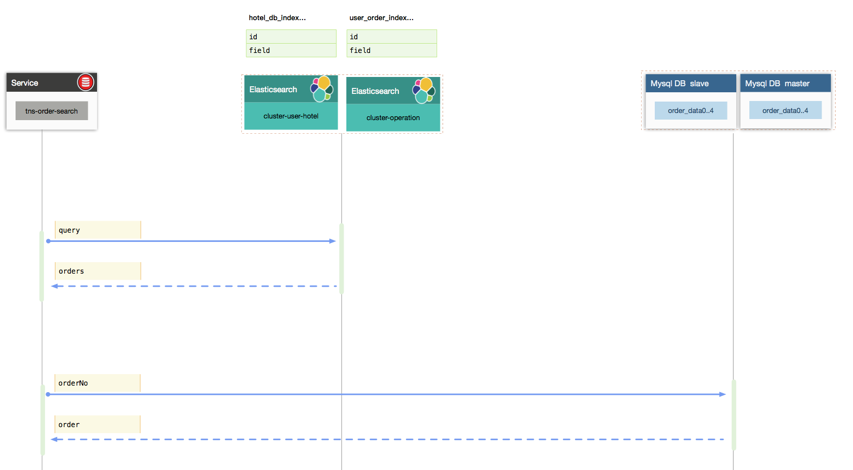
系统伸缩性:Elasticsearch 中索引设置了8个分片,目前ES单个索引的文档达到1.4亿,合计达到2亿条数据占磁盘大小64G,集群机器磁盘容量240G。
https://elasticsearch.cn/article/6197
4. Elasticsearch在58集团信息安全部的应用
全面介绍 Elastic Stack 在58集团信息安全部的落地,升级,优化以及应用。
包括如下几个方面:接入背景,存储选型,性能挑战,master node以及data node优化,安全实践,高吞吐量以及低延迟搜索优化;kibana 的落地,本地化使其更方便产品、运营使用。

https://elasticsearch.cn/slides/124
5. 滴滴Elasticsearch多集群架构实践
滴滴 2016 年初开始构建 Elasticsearch 平台,如今已经发展到超过 3500+ Elasticsearch 实例,超过 5PB 的数据存储,峰值写入 tps 超过了 2000w/s 的超大规模。
Elasticsearch 在滴滴有着非常丰富的使用场景,例如线上核心的打车地图搜索,客服、运营的多维度查询,滴滴日志服务等近千个平台用户。
先看看滴滴 Elasticsearch 单集群的架构:滴滴在单集群架构的时候,写入和查询就已经通过 Sink 服务和 Gateway 服务管控起来。
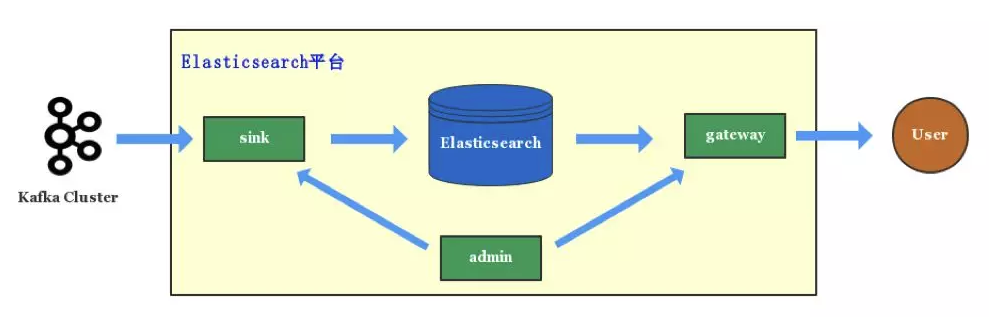
5.1. Sink 服务
滴滴几乎所有写入 Elasticsearch 的数据都是经由 kafka 消费入到 Elasticsearch。kafka 的数据包括业务 log 数据、mysql binlog 数据和业务自主上报的数据,Sink 服务将这些数据实时消费入到 Elasticsearch。
最初设计 Sink 服务是想对写入 Elasticsearch 集群进行管控,保护 Elasticsearch 集群,防止海量的数据写入拖垮 Elasticsearch,之后我们也一直沿用了 Sink 服务,并将该服务从 Elasticsearch 平台分离出去,成立滴滴 Sink 数据投递平台,可以从 kafka 或者 MQ 实时同步数据到 Elasticsearch、HDFS、Ceph 等多个存储服务。
有了多集群架构后,Elasticsearch 平台可以消费一份 MQ 数据写入多个 Elasticsearch 集群,做到集群级别的容灾,还能通过 MQ 回溯数据进行故障恢复。
5.2. Gateway 服务
所有业务的查询都是经过 Gateway 服务,Gateway 服务实现了 Elasticsearch 的 htp restful 和 tcp 协议,业务方可以通过 Elasticsearch 各语言版本的 sdk 直接访问 Gateway 服务
Gateway 服务还实现了 SQL 接口,业务方可以直接使用 SQL 访问 Elasticsearch 平台。
Gateway 服务最初提供了应用权限的管控,访问记录,限流、降级等基本能力,后面随着平台演进,Gateway 服务还提供了索引存储分离、DSL 级别的限流、多集群灾备等能力。
https://mp.weixin.qq.com/s/K44-L0rclaIM40hma55pPQ
6. Elasticsearch实用化订单搜索方案
搜索引擎中,主要考虑到Elasticsearch支持结构化数据查询以及支持实时频繁更新特性,传统订单查询报表的痛点,以及Elasticsearch能够帮助解决的问题。
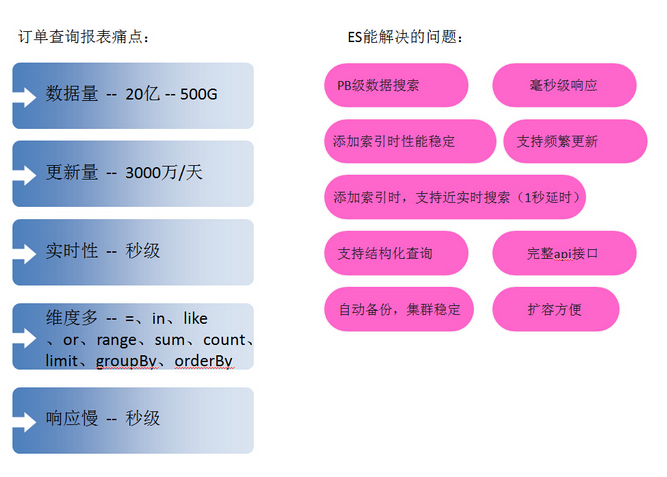
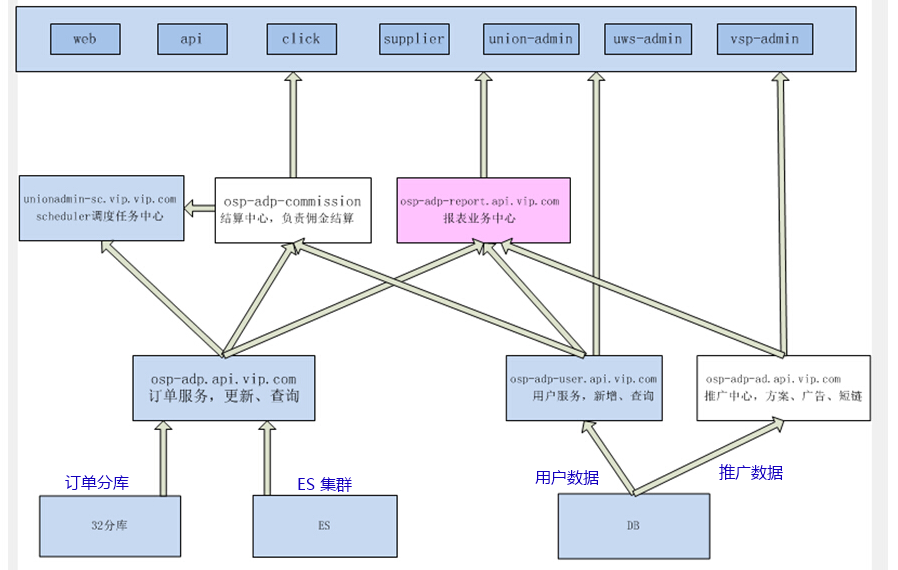
6.1. 订单搜索系统架构
整个业务线使用服务化方式,Elasticsearch集群和数据库分库,作为数据源被订单服务系统封装为对外统一接口;各前、后台应用和报表中心,使用服务化的方式获取订单数据。
https://my.oschina.net/u/2485991/blog/533163