Redis入门 - 数据类型:3种特殊类型
Redis除了上文中5种基础数据类型,还有三种特殊的数据类型,分别是 HyperLogLogs(基数统计), Bitmaps (位图) 和 geospatial (地理位置)。。
一、geospatial
1. 概述介绍
Redis 在 3.2 版本中加入了地理空间(geospatial)以及索引半径查询的功能,主要用在需要地理位置的应用上。将指定的地理空间位置(经度、纬度、名称)添加到指定的 key 中,这些数据将会存储到 sorted set。这样的目的是为了方便使用 GEORADIUS 或者 GEORADIUSBYMEMBER 命令对数据进行半径查询等操作。也就是说,推算地理位置的信息,两地之间的距离,周围方圆的人等等场景都可以用它实现。
这个功能可以推算地理位置的信息: 两地之间的距离,方圆几里的人,比如朋友的定位,附近的人,打车距离实现。
所有的geospatial命令都是geo开头的。
2. 相关命令
1. geoadd
添加地理位置
127.0.0.1:6379> geoadd china:city 118.76 32.04 manjing 112.55 37.86 taiyuan 123.43 41.80 shenyang
(integer) 3
127.0.0.1:6379> geoadd china:city 144.05 22.52 shengzhen 120.16 30.24 hangzhou 108.96 34.26 xian
(integer) 3
使用geoadd规则
- 地球的两极无法直接添加, 我们一般会下载城市数据, 通过java程序一次性导入;
- 参数key经度(longitude) 纬度(latitude) 名称。
2. geopos
获取指定的成员的经度和纬度
127.0.0.1:6379> geopos china:city taiyuan manjing
1) 1) "112.54999905824661255"
2) "37.86000073876942196"
2) 1) "118.75999957323074341"
2) "32.03999960287850968"
获得当前定位, 一定是一个坐标值!
3. geodist
如果不存在,返回空。 单位如下:
m 表示单位为米。
km 表示单位为千米。
mi 表示单位为英里。
ft 表示单位为英尺。
127.0.0.1:6379> geodist china:city taiyuan shenyang m
"1026439.1070"
127.0.0.1:6379> geodist china:city taiyuan shenyang km
"1026.4391"
4. georadius
附近的人 ==> 获得所有附近的人的地址,定位,通过半径来查询。
获得指定数量的人
127.0.0.1:6379> georadius china:city 110 30 1000 km 以 100,30 这个坐标为中心, 寻找半径为1000km的城市
1) "xian"
2) "hangzhou"
3) "manjing"
4) "taiyuan"
127.0.0.1:6379> georadius china:city 110 30 500 km
1) "xian"
127.0.0.1:6379> georadius china:city 110 30 500 km withdist
1) 1) "xian"
2) "483.8340"
127.0.0.1:6379> georadius china:city 110 30 1000 km withcoord withdist count 2
1) 1) "xian"
2) "483.8340"
3) 1) "108.96000176668167114"
2) "34.25999964418929977"
2) 1) "manjing"
2) "864.9816"
3) 1) "118.75999957323074341"
2) "32.03999960287850968"
参数 key 经度 纬度 半径 单位 [显示结果的经度和纬度] [显示结果的距离] [显示的结果的数量]
5. georadiusbymember
显示与指定成员一定半径范围内的其他成员
127.0.0.1:6379> georadiusbymember china:city taiyuan 1000 km
1) "manjing"
2) "taiyuan"
3) "xian"
127.0.0.1:6379> georadiusbymember china:city taiyuan 1000 km withcoord withdist count 2
1) 1) "taiyuan"
2) "0.0000"
3) 1) "112.54999905824661255"
2) "37.86000073876942196"
2) 1) "xian"
2) "514.2264"
3) 1) "108.96000176668167114"
2) "34.25999964418929977"
参数与 georadius 一样
6. geohash(较少使用)
该命令返回11个字符的hash字符串
127.0.0.1:6379> geohash china:city taiyuan shenyang
1) "ww8p3hhqmp0"
2) "wxrvb9qyxk0"
将二维的经纬度转换为一维的字符串, 如果两个字符串越接近, 则距离越近
3. 底层
geo底层的实现原理实际上就是Zset, 我们可以通过Zset命令来操作geo
127.0.0.1:6379> type china:city
zset
查看全部元素 删除指定的元素
127.0.0.1:6379> zrange china:city 0 -1 withscores
1) "xian"
2) "4040115445396757"
3) "hangzhou"
4) "4054133997236782"
5) "manjing"
6) "4066006694128997"
7) "taiyuan"
8) "4068216047500484"
9) "shenyang"
10) "4072519231994779"
11) "shengzhen"
12) "4154606886655324"
127.0.0.1:6379> zrem china:city manjing
(integer) 1
127.0.0.1:6379> zrange china:city 0 -1
1) "xian"
2) "hangzhou"
3) "taiyuan"
4) "shenyang"
5) "shengzhen"
二、hyperloglog
1. 什么是基数估算?
HyperLogLog 是一种基数估算算法。所谓基数估算,就是估算在一批数据中,不重复元素的个数有多少。
从数学上来说,基数估计这个问题的详细描述是:对于一个数据流 {x1,x2,...,xs} 而言,它可能存在重复的元素,用 n 来表示这个数据流的不同元素的个数,并且这个集合可以表示为{e1,...,en}。目标是:使用 m 这个量级的存储单位,可以得到 n 的估计值,其中 m<<n 。并且估计值和实际值 n 的误差是可以控制的。
对于上面这个问题,如果是想得到精确的基数,可以使用字典(dictionary)这一个数据结构。对于新来的元素,可以查看它是否属于这个字典;如果属于这个字典,则整体计数保持不变;如果不属于这个字典,则先把这个元素添加进字典,然后把整体计数增加一。当遍历了这个数据流之后,得到的整体计数就是这个数据流的基数了。
这种算法虽然精准度很高,但是使用的空间复杂度却很高。那么是否存在一些近似的方法,可以估算出数据流的基数呢?HyperLogLog 就是这样一种算法,既可以使用较低的空间复杂度,最后估算出的结果误差又是可以接受的。
2. hyperLogLog 算法简介
HyperLogLog 算法的基本思想来自伯努利过程。
伯努利过程就是一个抛硬币实验的过程。抛一枚正常硬币,落地可能是正面,也可能是反面,二者的概率都是 1/2 。伯努利过程就是一直抛硬币,直到落地时出现正面位置,并记录下抛掷次数k。比如说,抛一次硬币就出现正面了,此时 k 为 1; 第一次抛硬币是反面,则继续抛,直到第三次才出现正面,此时 k 为 3。
那么如何通过伯努利过程来估算抛了多少次硬币呢?还是假设 1 代表抛出正面,0 代表反面。连续出现两次 0 的序列应该为“001”,那么它出现的概率应该是三个二分之一相乘,即八分之一。那么可以估计大概抛了 8 次硬币。
HyperLogLog 原理思路是通过给定 n 个的元素集合,记录集合中数字的比特串第一个1出现位置的最大值k,也可以理解为统计二进制低位连续为零(前导零)的最大个数。通过k值可以估算集合中不重复元素的数量m,m近似等于 2^k。

如上图所示,给定一定数量的用户,通过 Hash 算法得到一串Bitstring,记录其中最大连续零位的计数为 4,User 的不重复个数为 2 ^ 4 = 16。
分桶优化
HyperLogLog的基本思想是利用集合中数字的比特串第一个1出现位置的最大值来预估整体基数,但是这种预估方法存在较大误差,为了改善误差情况,HyperLogLog中引入分桶平均的概念,计算 m 个桶的调和平均值。下面公式中的const是一个修正常量。
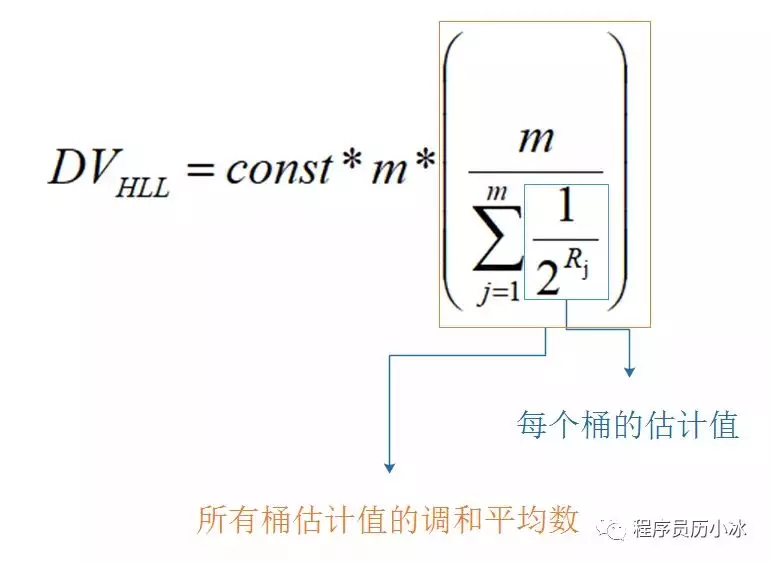
Redis中HyperLogLog一共分了2^14个桶,也就是16384个桶。每个桶中是一个6 bit 的数组,如下图所示。

HyperLogLog将上文所说的64位比特串的低14位单独拿出,它的值就对应桶的序号,然后将剩下 50 位中第一次出现 1 的位置值设置到桶中。50位中出现1的位置值最大为50,所以每个桶中的 6 位数组正好可以表示该值。
在设置前,要设置进桶的值是否大于桶中的旧值,如果大于才进行设置,否则不进行设置。示例如下图所示。

在计算近似基数时,就分别计算每个桶中的值,带入到上文将的 DV 公式中,进行调和平均和结果修正,就能得到估算的基数值。
3. 测试使用
127.0.0.1:6379> pfadd mykey a b c d e f g h i j
(integer) 1
127.0.0.1:6379> pfcount mykey
(integer) 10
127.0.0.1:6379> pfadd mykey2 i j z x c v b n m
(integer) 1
127.0.0.1:6379> pfcount mykey2
(integer) 9
127.0.0.1:6379> pfmerge mykey3 mykey mykey2
OK
127.0.0.1:6379> pfcount mykey3
(integer) 15
- pfadd 创建一组元素
- pfcount 统计元素中的基数数量
- pfmerge 合并两组,参数为pfmerge并集,来源... 会去掉相同的元素。
三、bitmaps
1. 简介
位存储, one hot编码
统计用户信息, 活跃, 不活跃! 登录, 未登录! 打卡, 365打卡!
只有两个状态的, 都可以使用bitmaps!
Bitmaps 位图, 数据结构, 都是操作二进制位来进行记录, 只有 0 和 1 两个状态
例如:365天 = 365 bit 1字节 = 8 bit ==> 只需要 46 个字节左右就可以存储用户的一年打卡的信息了!
2. 测试
使用bitmap来记录周一至周日的打卡,比如周一: 1 周二: 0 ...,判断有几天值是1就可以了。
127.0.0.1:6379> setbit sign 0 1
(integer) 0
127.0.0.1:6379> setbit sign 1 0
(integer) 0
127.0.0.1:6379> setbit sign 2 0
(integer) 0
127.0.0.1:6379> setbit sign 3 1
(integer) 0
127.0.0.1:6379> setbit sign 4 1
(integer) 0
127.0.0.1:6379> setbit sign 5 1
(integer) 0
127.0.0.1:6379> setbit sign 6 0
(integer) 0
setbit key offset value,其中value参数只能为0和1,offset从0开始。
查看某一天是否有打卡
getbit key value
127.0.0.1:6379> getbit sign 5
(integer) 1
同级操作,统计打卡的天数( 1的个数 )
bitcount key
127.0.0.1:6379> bitcount sign
(integer) 4